Apuntes y cursos para estudiantes
Estadística
La estadística: es una ciencia formal referente a la recolección, análisis e interpretación de datos, ya sea para ayudar en la resolución de la toma de decisiones o para explicar condiciones regulares o irregulares de algún fenómeno o estudio aplicado .
la poblacion: es el conjunto de elementos de referencia sobre el que se realizan los estudios estadisticos.
muestra en estadistica :es un subconjunto de casos o individuos de una población estadística.
TIPOS DE VARIABLES:Variables CUALITATIVAS, que son aquellas que no necesitan números para expresarse; cada forma particular en que pueden presentarse se denomina modalidad. Por ejemplo, el sexo de una persona es una variable cualitativa y varón o mujer son sus únicas modalidades. las variables cuantitativas DISCRETAS, cuyos valores son aislados (habitualmente números enteros), de forma que pueden enumerarse y existen valores consecutivos entre los que no puede haber otro; Por ejemplo, un resumen puede tener 349 ó 350, pero no 349.17 palabras.las variables cuantitativas CONTINUAS, que pueden tomar cualquier valor numérico, entero o decimal, de forma que teóricamente entre dos valores posibles siempre se pueden encontrar otros (entre 65.3 Kg. y 65.4 Kg. de peso siempre está 65.37 Kg., por ejemplo
DIAGRAMAS DE REPRESENTACION:Diagrama de sectores:Está representación gráfica consiste en dividir un círculo en tantos sectores circulares como modalidades presente el carácter cualitativo, asignando un ángulo central a cada sector circular proporcional a la frecuencia absoluta n. Diagrama de barras:Consiste en levantar, para cada valor de la variable, una barra cuya altura sea su frecuencia absoluta o relativa, dependiendo de la distribución de frecuencias que estemos representando. Histograma:Al ser esta representación una representación por áreas, hay que distinguir si los intervalos en los que aparecen agrupados los datos son de igualamplitud o no.Si la amplitud de los intervalos es constante, dicha amplitud puede tomarse como unidad. Si los intervalos tienen diferente amplitud, se toma alguna de ellas como unidad (generalmente la menor).Tambien existen los pictogramas,los diagramas de frecuencias acumuladas y los diagramas de rectangulos.Muestreo aleatorio simple:para obtener una muestra,se numeran los elemento de la poblacion y se seleccionas al azar los n elementos que contiene la muestra.
Muestreo sistemático:En este caso se elige el primer individuo al azar y el resto viene condicionado por aquél. Este método es muy simple de aplicar en la práctica y tiene la ventaja de que no hace falta disponer de un marco de encuesta elaborado. Puede aplicarse en la mayoría de las situaciones, la única precaución que debe tenerse en cuenta es comprobar que la característica que estudiamos no tenga una periodicidad que coincida con la del muestreo (por ejemplo elegir un día de la semana para tomar muestras en un matadero, ya que muchos ganaderos suelen sacrificar un día determinado).
Muestreo aleatorio estratificado. Se divide la población en grupos en función de un carácter determinado y después se muestrea cada grupo aleatoriamente, para obtener la parte proporcional de la muestra. Este método se aplica para evitar que por azar algún grupo de animales este menos representado que los otros.
Muestreo aleatorio por conglomerados. Se divide la población en varios grupos de características parecidas entre ellos y luego se analizan completamente algunos de los grupos, descartando los demás. Dentro de cada conglomerado existe una variación importante, pero los distintos conglomerados son parecidos. Requiere una muestra más grande, pero suele simplificar la recogida de muestras. Frecuentemente los conglomerados se aplican a zonas geográficas.
Medidas de centralizacion
Media aritmetica:Llamando xl, …, xk a los datos distintos de un carácter en estudio, o las marcas de clase de los intervalos en los que se han agrupado dichos datos, y ni,…, nk a las correspondientes frecuencias absolutas de dichos valores o marcas de clase, llamaremos media aritmética de la distribución de frecuencias a .La mediana: es otra medida de posición, la cual se define como aquel valor de la variable tal que, supuestos ordenados los valores de ésta en orden creciente, la mitad son menores o iguales y la otra mitad mayores o iguales.
.La mediana: es otra medida de posición, la cual se define como aquel valor de la variable tal que, supuestos ordenados los valores de ésta en orden creciente, la mitad son menores o iguales y la otra mitad mayores o iguales.
La moda: se define como aquel valor de la variable al que corresponde máxima frecuencia (absoluta o relativa). Para calcularla, también será necesario distinguir si los datos están o no agrupados.
Medidas de posicion:Cuartiles:Los cuartiles son los tres valores de la variable que dividen a un conjunto de datos ordenados en cuatro partes iguales.Q1, Q2 y Q3 determinan los valores correspondientes al 25%, al 50% y al 75% de los datos.Q2 coincide con la mediana.
Los deciles: son los nueve valores que dividen la serie de datos en diez partes iguales.Los deciles dan los valores correspondientes al 10%, al 20%… y al 90% de los datos.D5 coincide con la mediana.
Los percentiles: son los 99 valores que dividen la serie de datos en 100 partes iguales.Los percentiles dan los valores correspondientes al 1%, al 2%… y al 99% de los datos.P50 coincide con la mediana.
El rango intercuartílico: es una medida de variabilidad adecuada cuando la medida de posición central empleada ha sido la mediana .Se define como la diferencia entre el tercer cuartil y el primer cuartil
MEDIDAS DE DISPERSION:RANGO:La diferencia entre el menor y el mayor valor.En {4, 6, 9, 3, 7} el menor valor es 3, y el mayor es 9, entonces el rango es 9-3 igual a 6.
La desviación media: es la media aritmética de los valores absolutos de las desviaciones respecto a la media.La desviación media se representa por 
 .
.
La varianza: es la media aritmética del cuadrado de las desviaciones respecto a la media de una distribución estadística.La varianza se representa por  .
.  .
.
La desviación típica: es la raíz cuadrada de la varianza.Es decir, la raíz cuadrada de la media de los cuadrados de las puntuaciones de desviación.La desviación típica se representa por .  .
.
El coeficiente de variación: es la relación entre la desviación típica de una muestra y su media. El coeficiente de variación se suele expresar en porcentajes.el coeficiente de variación permite comparar las dispersiones de dos distribuciones distintas, siempre que sus medias sean positivas.Se calcula para cada una de las distribuciones y los valores que se obtienen se comparan entre sí.La mayor dispersión corresponderá al valor del coeficiente de variación mayor.
VARIABLE BIDIMENSIONAL:Las variables estadísticas bidimensionales: las representaremos por el par (X,Y), donde X es una variable unidimensional que toma los valores x1,x2,….,xn e Y es otra variable unidimensional que toma los valores y1,y2,….,yn. Por tanto, la v.e. bidimensional (X,Y) toma valores (x1,y1),(x2,y2),….,(xn,yn).
Tabla bidimensional simple: Está formada por tres filas o columnas en las que se representan ordenadamente los valores de las variables y sus frecuencias. Está indicada para casos con pocos datos y pocos valores o ninguno repetidos. Es la tabla correspondiente al ejemplo de la página anterior.
Tabla de doble entrada. Está formada por tantas filas y columnas como valores tengamos de cada una de las variables, más una fila y una columna más para indicar los totales. Está indicada para casos con bastantes datos, en los que para cada valor de una variable, existen varios valores de la otra.
Diagrama de dispersión :es un tipo de diagrama matemático que utiliza las coordenadas cartesianas para mostrar los valores de dos variables para un conjunto de datos.Los datos se muestran como un conjunto de puntos, cada uno con el valor de una variable que determina la posición en el eje horizontal y el valor de la otra variable determinado por la posición en el eje vertical.Un diagrama de dispersión se llama también gráfico de dispersión.
Covarianza: de una variable bidimensional es la media aritmética de los productos de las desviaciones de cada una de las variables respecto a sus medias respectivas.La covarianza se representa por sxy o óxy.La covarianza indica el sentido de la correlación entre las variables.Si óxy > 0 la correlación es directa.Si óxy < 0 la correlación es inversa.La covarianza presenta como inconveniente, el hecho de que su valor depende de la escala elegida para los ejes.Es decir, la covarianza variará si expresamos la altura en metros o en centímetros. También variará si el dinero lo expresamos en euros o en dólares.
La correlación: trata de establecer la relación o dependencia que existe entre las dos variables que intervienen en una distribución bidimensional.Es decir, determinar si los cambios en una de las variables influyen en los cambios de la otra. En caso de que suceda, diremos que las variables están correlacionadas o que hay correlación entre ellas.
Tipos de correlacion: Correlación directa:La correlación directa se da cuando al aumentar una de las variables la otra aumenta.La recta correspondiente a la nube de puntos de la distribución es una recta creciente.
Correlación inversa:La correlación inversa se da cuando al aumentar una de las variables la otra disminuye.La recta correspondiente a la nube de puntos de la distribución es una recta decreciente.
Correlación nula:La correlación nula se da cuando no hay dependencia de ningún tipo entre las variables.En este caso se dice que las variables son incorreladas y la nube de puntos tiene una forma redondeada.
El coeficiente de correlación lineal: es el cociente entre la covarianza y el producto de las desviaciones típicas de ambas variables.El coeficiente de correlación lineal se expresa mediante la letra r.Propiedades del coeficiente de correlación:
1. El coeficiente de correlación no varía al hacerlo la escala de medición.Es decir, si expresamos la altura en metros o en centímetros el coeficiente de correlación no varía.
2. El signo del coeficiente de correlación es el mismo que el de la covarianza.Si la covarianza es positiva, la correlación es directa.Si la covarianza es negativa, la correlación es inversa.Si la covarianza es nula, no existe correlación.
3. El coeficiente de correlación lineal es un número real comprendido entre ?1 y 1.?1 ? r ? 1
4. Si el coeficiente de correlación lineal toma valores cercanos a ?1 la correlación es fuerte e inversa, y será tanto más fuerte cuanto más se aproxime r a ?1.
5. Si el coeficiente de correlación lineal toma valores cercanos a 1 la correlación es fuerte y directa, y será tanto más fuerte cuanto más se aproxime r a 1.
6. Si el coeficiente de correlación lineal toma valores cercanos a 0, la correlación es débil.
7. Si r = 1 ó ?1, los puntos de la nube están sobre la recta creciente o decreciente. Entre ambas variables hay dependencia funcional.
Hipotesis estadistica: Dentro de la inferencia estadística, un contraste de hipótesis (también denominado test de hipótesis), es un procedimiento para juzgar si una propiedad que se supone que cumple una población estadística es compatible con lo observado en una muestra de dicha población.
Estimacion puntual:Fenómeno en el que a partir de las observaciones de una muestra se calcula un solo valor como estimación de un parámetro de la población desconocido, el procedimiento se denomina estimación puntual. El error suele ser alto este puede disminuir, si el numero de muestras para el calculo del parámetro sea elevado. O bien viendo que las estadísticas obtenidas son validas.
Estimacio por intervalos:Consiste en la obtención de un intervalo dentro del cual estará el valor del parámetro estimado con una cierta probabilidad.El error de la estimación es una medida de precisión que se corresponde con la amplitud del intervalo de confianza. Para mayor precisión en la estimación del parámetro, más estrecho deberá ser el intervalo de confianza. Para un menor el error mayor ha de ser el número de sujetas que realicen la muestra a estudiar.
Intervalo de confianza: Se llama intervalo de confianza a un par de números entre los cuales se estima que estará cierto valor desconocido con una determinada probabilidad de acierto. Formalmente, estos números determinan un intervalo, que se calcula a partir de datos de una muestra . El valor desconocido es un parámetro poblacional.
Nivel de confianza:El nivel de confianza es la probabilidad de que el parámetro a estimar se encuentre en el intervalo de confianza. El nivel de confianza (p) se designa mediante 1 ? ?, y se suele tomar en tanto por ciento. Los niveles de confianza más usuales son: 90%; 95% y 99%.
Error admisible: Como el nombre indica es el posible error a tener depende del intervalo de confiaanza. El error se puede calcular con la formula.E=(Z(x/2)*A/raiz cuadrada de n.
Variable aleatoria continua es una función X que asigna a cada resultado posible de un experimento un número real. Si X puede asumir cualquier valor en algun intervalo I (el intervalo puede ser acotado o desacotado), se llama una variable aleatoria continua. Si puede asumir solo varios valores distintos, se llama una variable aleatoria discreta.
Funcion de densidad:La función de densidad de una variable aleatoria X permite trasladar la medida de probabilidad o «suerte» de realización de los sucesos de una experiencia aleatoria a la característica numérica que define la variable aleatoria. propiedads.a)El área total encerrada bajo la curva es igual a 1.b)f(x)<que 0 en todo x.
Distribución t (de Student): es una distribución de probabilidad que surge del problema de estimar la media de una población normalmente distribuida cuando el tamaño de la muestra es pequeño.
Distribucion f snedecor:Usada en teoría de probabilidad y estadística , la distribución F es una distribución de probabilidad continua . También se la conoce como distribución F de Snedecor (por George Snedecor )o como distribución F de Fisher-Snedecor.
Variable aleatoria continua:Una variable aleatoria X es continua si su función de distribución es una función continua.En la práctica, se corresponden con variables asociadas con experimentos en los cuales la variable medida puede tomar cualquier valor en un intervalo: mediciones biométricas, intervalos de tiempo, áreas, etc.
Distribucion exponencial: En estadística la distribución exponencial es una distribución de probabilidad continua con un parámetro λ > 0 cuya función de densidad es:

El valor esperado y la varianza de una variable aleatoria X con distribución exponencial son E(x)= (1/L).
Distribución X2 (de Pearson), :llamada Chi cuadrado o Ji cuadrado, es una distribución de probabilidad continua con un parámetro k que representa los grados de libertad de la variable aleatoria

donde Zi son variables aleatorias normales independientes de media cero y varianza 1.
Distribucion uniforme:Se dice que una v.a. X posee una distribución uniforme en el intervalo [a,b],

si su función de densidad es la siguiente:

Distribucion normalo de Gaus: En estadística y probabilidad se llama distribución normal, distribución de Gauss o distribución gaussiana, a una de las distribuciones de probabilidad de variable continua que con más frecuencia aparece aproximada en fenómenos reales. La grafica tiene forma acampanada y es simetrica.
Variable aleatoria: Una variable es aleatoria si su valor está determinado por el azar. En gran número de experimentos aleatorios es necesario, para su tratamiento matemático, cuantificar los resultados de modo que se asigne un número real a cada uno de los resultados posibles del experimento. De este modo se establece una entre elementos del espacio muestral asociado al experimento y números reales.
Distribucion geometrica:La distribución geométrica es cualquiera de las dos distribuciones de probabilidad discretas siguientes:A)la distribución de probabilidad del número X del ensayo de Bernoulli necesaria para obtener un éxito, contenido en el conjunto { 1, 2, 3,…} o B) la distribución de probabilidad del número Y = X ? 1 de fallos antes del primer éxito, contenido en el conjunto { 0, 1, 2, 3,… }.Cual de éstas es la que uno llama «la» distribución geométrica, es una cuestión de convención y conveniencia.
Distr. binomial negativa:La distribución binomial es una distribución de probabilidad discreta que incluye a la distribución de Pascal.El número de experimentos de Bernoulli de parámetro ? independientes realizados hasta la consecución del k-ésimo éxito es una variable aleatoria que tiene una distribución binomial negativa con parámetros k y ?.
Distr. Bernoulli:La distribución de Bernoulli (o distribución dicotómica), nombrada así por elmatemático suizo Jakob Bernoulli es una distribución de probabilidad discreta , que toma valor 1 para la probabilidad de éxito (p) y valor 0 para la probabilidad de fracaso (q = 1 − p) .Si X es una variable aleatoria que mide «número de éxitos», y se realiza un único experimento con dos posibles resultados (éxito o fracaso), se dice que la variable aleatoria X se distribuye como una Bernoulli de parámetro P.
Distr. binomial:La distribución binomial es una distribución de probabilidad discreta que mide el número de éxitos en una secuencia de n ensayos de Bernoulli independientes entre sí, con una probabilidad fija p de ocurrencia del éxito entre los ensayos.
La probabilidad:Mide de la frecuencia con la que se obtiene un resultado (o conjunto de resultados) al llevar a cabo un experimento aleatorio, del que se conocen todos los resultados posibles, bajo condiciones suficientemente estables. La teoría de la probabilidad se usa extensamente en áreas como la estadística ,la física , la matemática ,laciencia y la filosofía para sacar conclusiones de algo.
Probabilidad condicionada es la probabilidad de que ocurra un evento A, sabiendo que también sucede otro evento B. La probabilidad condicional se escribe P(A|B), y se lee «la probabilidad de A dado B.No tiene por qué haber una relación causal o temporal entre A y B. A puede preceder en el tiempo a B, sucederlo o pueden ocurrir simultáneamente.A puede causar B, viceversa o pueden no tener relación causal. Las relaciones causales o temporales son nociones que no pertenecen al ámbito de la probabilidad.
Probabilidad compuesta:se deriva de la probabilidad condicionada:La probabilidad de que se den simultáneamente dos sucesos es igual a la probabilidad a priori del suceso A multiplicada por la probabilidad del suceso B condicionada al cumplimiento del suceso A.La fórmula para calcular esta probabilidad compuesta es:

Probabilidad todal: Sea A1, A2, …,An un sistema completo de sucesos tales que la probabilidad de cada uno de ellos es distinta de cero, y sea B un suceso cualquier del que se conocen las probabilidades condicionales P(B/Ai), entonces la probabilidad del suceso B viene dada por la expresión:

Teorema de Bayes: expresa la probabilidad condicional de un evento aleatorio A dado B en términos de la distribución de probabilidad condicional del evento B dado A y la distribución de probabilidad marginal de sólo A.En términos más generales y menos matemáticos, el teorema de Bayes es de enorme relevancia puesto que vincula la probabilidad de A dado B con la probabilidad de B dado A.
Experimentos aleatorias:es aquel que bajo el mismo conjunto aparente de condiciones iniciales, puede presentar resultados diferentes, es decir, no se puede predecir el resultado exacto de cada experiencia particular. Este tipo de fenómeno es opuesto al fenómeno determinista ,en el que conocer todos los factores de un experimento nos hace predecir exactamente el resultado del mismo.
Espacio muestral suceso: consiste en el conjunto de todos los posibles resultados individuales de un experimento aleatorio . Para algunos tipos de experimento puede haber dos o más espacios de muestreo posibles
Union:Suceso que verifica si se verifica A o se veriica B o se verifican ambos(AUB).
Interseccion:Verifica si se verifica A O B . La intersecion de sucesos se verifica por A Y B.
Sucesos incompatibles:Son aquellos que no se pueden verificar simultaneamente. Cuando pueden verificarse ambos a la vez se llaman compatibles. Si A y B son incompatibles enonces A B= Ø Si A y B son compatibles entonces A y B Ø .
Suceso:Un suceso es cada uno de los resultados posibles de una experiencia aleatoria.
Nube de punto: Representación gráfica realizada mediante un dibujo en un sistema bidimensional de coordenadas cartesianas. En este tipo de diagramas cada punto representa la puntuación que el sujeto obtiene en las dos variables, determinando su puntuación por la lectura de los valores que aparecen en la escala vertical y horizontal.
Regre. Lineal: método matemático que modeliza la relación entre una variable dependiente Y, lasvariables independientes Xi y un término aleatorio.Este modelo puede ser expresado como: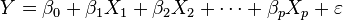
Regre no lineal:la regresión no lineal es un problema de inferencia Como mínimo, se pretende obtener los valores de los parámetros asociados con la mejor curva de ajuste , Con el fin de determinar si el modelo es adecuado .